오늘 작성해볼 내용은
유튜브의 제목과 URL을 크롤링하고 그 결과를 엑셀파일로 저장합니다.
다시한번 실행했을 때는 기존의 엑셀파일에 시트를 만들고 그 결과를 저장합니다.
그런 식으로 검색 결과를 하나의 엑셀파일에 저장하는 내용입니다.
먼저 지난번에 포스팅 했던 글을 읽고 오시는 것을 추천드립니다.
1. 파이썬 셀레니움 웹페이지 자동 스크롤 하기(Python Selenium scroll webpage)
◆ 로직
우선 YouTube.xlsx 라는 파일에 유튜브 크롤링 결과를 저장하는 것으로 정하겠습니다.
그러면 먼저 YouTube.xlsx 파일을 불러봅니다.
YouTube.xlsx 파일이 없다면 새로 생성하고 불러옵니다.
만약 YouTube.xlsx 파일이 새로 만들어진 파일이라면
첫번째 시트를 제외한 모든 시트를 지우고
첫번째 시트의 이름을 [ 검색어(날짜 시간) ]으로 변경하고
크롤링 결과를 저장합니다.
기존에 YouTube.xlsx 파일이 있다면
마지막 시트에 [ 검색어(날짜 시간) ]의 이름을 갖는 시트를 만들고
크롤링 결과를 저장합니다.
◆ 코드작성
from openpyxl import Workbook
from openpyxl import load_workbook
먼저 위와 같이 필요한 모듈을 import 해줍니다.
search_word = input("YouTube 검색어를 입력하세요 : ")
그리고 크롤링할 검색어를 입력 받습니다.
먼저 엑셀 파일을 불러와 보고
없다면, 파일을 하나 생성합니다.
try:
wb = load_workbook("X:\블로그\python\YouTube\YouTube.xlsx")
check_new_file = 0
except:
wb = Workbook()
check_new_file = 1
try ~ except 는 먼저 try 아래쪽 구문을 실행해 본 후
에러가 발생하면 except 아래쪽 구문을 실행합니다.
에러가 발생하지 않는다면 except 아래쪽 구문은 실행되지 않습니다.
먼저 해당경로에 YouTube.xlsx 파일이 있다면
파일을 불러오게 됩니다.
파일이 없다면 엑셀파일을 하나 만듭니다.
check_new_file 은 이 파일이 새로 만든건지 기존에 있던 파일인지
체크하는 변수입니다.
if check_new_file == 1:
while len(wb.sheetnames) > 1:
wb.remove(wb.sheetnames[len(wb.sheetnames)-1])
ws = wb.active
ws.title = search_word+time.strftime("(%Y-%m-%d %H-%M-%S)")
else:
ws = wb.create_sheet(search_word+time.strftime("(%Y-%m-%d %H-%M-%S)"))
이제 해당 파일이 새로 만들어진 파일인지 검사를 합니다.
위에서 파일을 새로 만들게 되면 check_new_file에 1이라는 값을 저장했었습니다.
만약 check_new_file의 값이 1 이라면(즉, 새로 만들어진 파일이라면)
해당 파일(workbook)의 모든 시트의 갯수를 셉니다.
len(wb.sheetnames) //시트의 갯수를 세는 코드입니다.
그리고 시트의 갯수가 1보다 많으면 계속해서 while 아래의 구문을 실행합니다.
시트의 갯수가 1개보다 많으면
시트를 하나씩 지워줍니다.
시트를 지울 때는 wb.remove() 함수를 사용합니다.
첫번째 시트의 인덱스는 0으로 시작합니다.
엑셀파일을 처음 생성하면 설정된 옵션에 따라 생성되는 시트가 다릅니다.
보통은 별다른 설정을 하지 않았다면
처음 엑셀파일을 만들면 3개의 시트가 생성되로록 설정되어 있는 것으로 알고 있습니다.
그럼 len(wb.sheetnames) 를 실행할 시 [ 3 ]이라는 결과가 나옵니다.
첫번째 시트의 인덱스 번호는 0이므로
세번째 시트의 인덱스 번호는 2가 됩니다.
wb.remove(wb.sheetnames[len(wb.sheetnames)-1])
wb.remove() 함수를 이용해 시트를 지우는데,
wb.sheetnames 의 목록에 들어있는 시트들 중인덱스 번호가 2인 즉, 가장 마지막의 시트를 지웁니다.
그런데도 아직 시트의 총 갯수는 2개로 1개보다 많습니다.다시한번 while 문이 실행되고 시트의 갯수가 1개가 될때까지 계속 실행되어결국에는 1개의 시트만 남게됩니다.
if check_new_file == 1:
while len(wb.sheetnames) > 1:
wb.remove(wb.sheetnames[len(wb.sheetnames)-1])
ws = wb.active
ws.title = search_word+time.strftime("(%Y-%m-%d %H-%M-%S)")
else:
ws = wb.create_sheet(search_word+time.strftime("(%Y-%m-%d %H-%M-%S)"))
ws = wb.active하나 남은 시트를 활성화 해줍니다.그리고 해당 시트의 이름을 앞서 입력한 검색어와 오늘 날짜를 합친 이름으로 설정합니다.search_word는 앞서 입력받은 검색어를 저장한 변수입니다.
time.strftime("(%Y-%m-%d %H-%M-%S)")은
날짜와 시간을 출력해주는 함수입니다.
사용하기 위해서는 time 모듈을 import 해야합니다.
우선 이렇게 사용하시면 됩니다.(대소문자를 구분합니다.)
다만, 엑셀의 시트 이름에 사용할 수 없는 특수문자는 사용이 불가합니다.
그렇기때문에 시간을 표시할 때 ( : )를 사용하지 않고 ( - )를 사용했습니다.
만약 새로 생성된 시트가 아니라면
시트를 하나 추가하고 시트의 이름을 동일하게 설정해 줍니다.
ws = wb.create_sheet(search_word+time.strftime("(%Y-%m-%d %H-%M-%S)"))
◆ 결과

위 그림과 같이 해당 폴더에 파일이 없습니다.
이 상태로 코드를 실행하여 유튜브에서 [ 파이썬 ]을 검색하여
검색된 결과가 제대로 엑셀파일에 저장되는 지 보겠습니다.

파일은 정상적으로 생성되었습니다.
이제 파일을 열어보겠습니다.
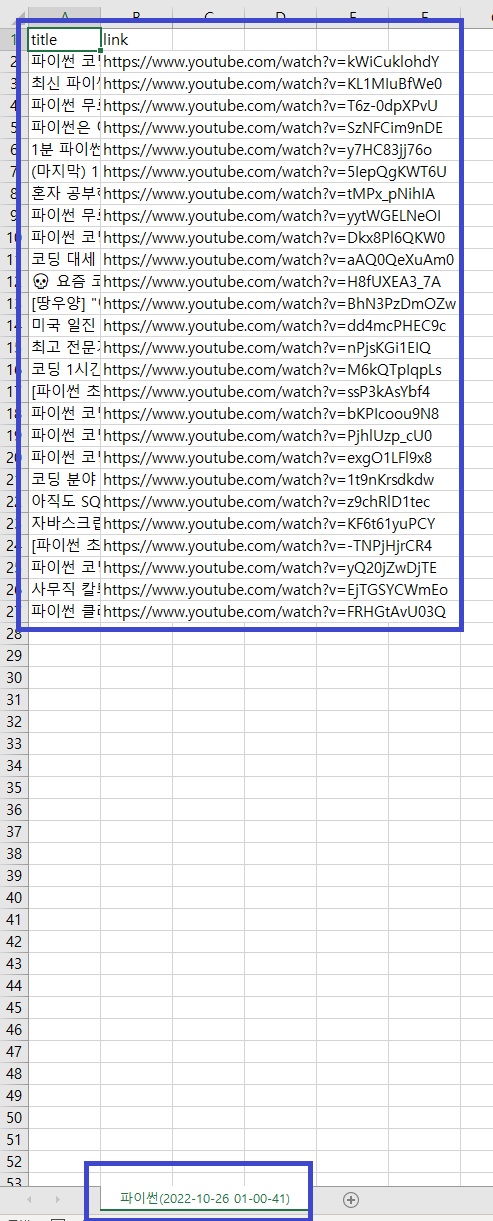
결과가 입력되었고, 시트이름도 정상적으로 변경이 되었습니다.
여기서 한번 더 검색하겠습니다.
이번 검색어는 [ 크롤링 ]입니다.

기존에 있던 파일에도 제대로 시트를 생성하고
결과를 저장합니다.
◆ 전체소스코드
from selenium import webdriver
# 여기부터는 앞서 포스팅한 내용입니다.
SCROLL_PAUSE_TIME = 2
# 여기부터 끝까지는 앞서 포스팅한 내용입니다.
wb.close()
여기를 방문하시면 더 많은 파이썬 관련 자료를 확인할 수 있습니다.
'파이썬(Python)' 카테고리의 다른 글
| [ OS ] python os.walk(), 폴더 경로, 파일 경로 확인하기 (0) | 2022.10.28 |
|---|---|
| [ 크롤링-selenium ] 파이썬 유튜브 크롤링(제목, URL, 조회수, 업데이트 날짜, 길이) (2) | 2022.10.27 |
| [ Basic ] 파이썬 패키지 관리 pip (0) | 2022.10.24 |
| [ 크롤링-pytube ] 파이썬 유튜브 동영상 다운로드(pytube YouTube videos Download) (0) | 2022.10.23 |
| [ 크롤링-Beautifulsoup ] Python Beautifulsoup select() [ (li, a), (li a), (li > a) ] (0) | 2022.10.23 |