◆ 웹 페이지 소스코드 확인하기

먼저 유튜브에 파이썬으로 검색한 후 [ F12 ]를 누르면 위와 같은 화면이 나타납니다.
위쪽 중간의 빨간색 네모 안의 아이콘을 누른 후
왼쪽 화면의 파란색 화면 부분을 눌러보시면
오른쪽 화면의 파란색 부분에 표시가 됩니다.
우선 오른쪽 화면의 표시된 부분이 왼쪽 화면의 제목에 해당하는 부분으로 보입니다.
다음으로 검색된 결과를 보니
동영상[파란색 네모 부문]도 있고 플레이리스트[보라색 네모 부문]도 있습니다.
우선은 플레이리스트를 제외하고 동영상의 제목과 URL을 가지고 올 생각이므로
두개의 차이점을 찾아보겠습니다.
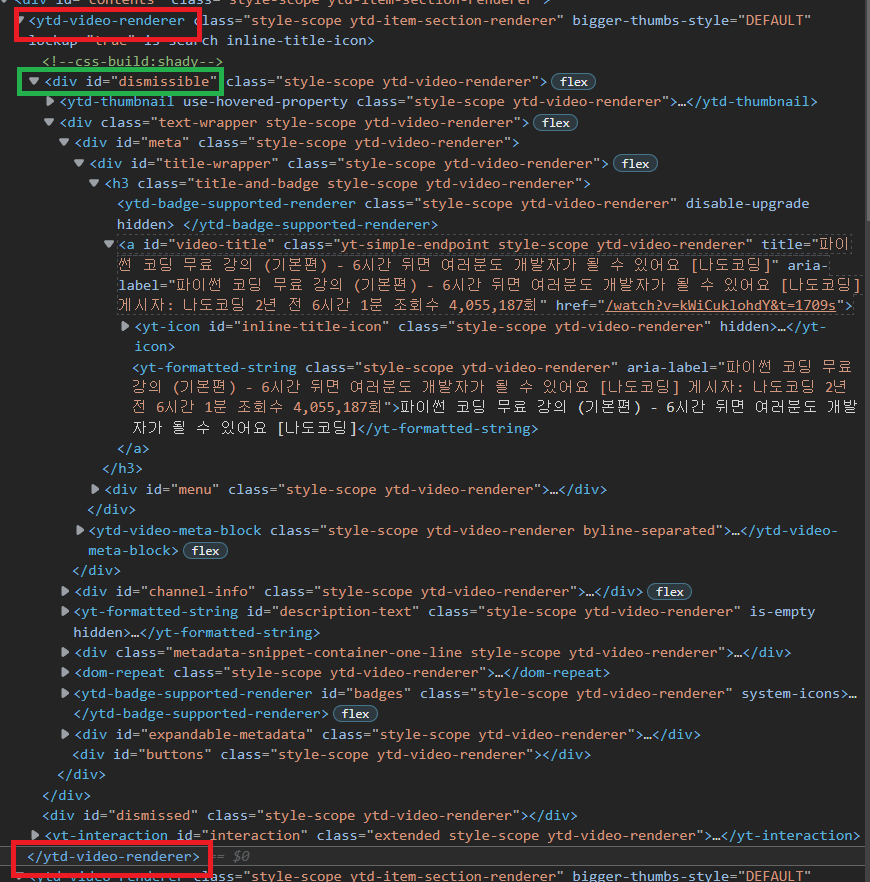

왼쪽은 동영상에 해당하는 부분의 소스코드이고
오른쪽은 플레이리스트에 해당하는 부분의 소스코드입니다.
동영상은 <ytd-video-renderer></ytd-video-renderer>로 감싸져 있고
플레이리스트는 <ytd-playlist-renderer></ytd-playlist-renderer>로 감싸져 있습니다.
또한
동영상에 해당하는 부분의 ID는 dismissible
플레이리스트에 해당하는 부분의 ID는 thumbnail 입니다.
두 부분의 ID가 다르므로 먼저 dismissible 부분을 가지고 오겠습니다.
selenium에서 요소 값을 불러오는 방법 중의 하나인
CSS_SELECTOR을 사용해 보겠습니다.
먼저 CSS_SELECTOR를 사용하기 위해서
from selenium.webdriver.common.by import By
를 추가해줍니다.
다음 dismissible 부분의 selector를 복사하겠습니다.

dismissible가 있는 부분에서 마우스 오른쪽 버튼을 누른 다음
[ 복사 ] → [ selector 복사 ]를 눌러줍니다.
그리고 우선 해당 값을 아무데나 복사해놓으세요
다음은 CSS_SELECTOR를 통해
ID가 dismissible에 접근할 수 있도록 모든 dismissible 아이디를 갖는 부분을
담아놓아 보겠습니다.
titles = driver.find_elements(By.CSS_SELECTOR, "#dismissible")
요소를 찾기 위해서는 find_elements 를 사용합니다.
그리고 CSS_SELECTOR를 사용한다는 의미로 By.CSS_SELECTOR를 입력하고
아까 복사한 selector를 붙어넣어 줍니다.
자 이제 titles라는 객체를 통해 유튜브 페이지에서 ID 값이 dismissible에 접근할 수 있습니다.

안쪽의 소스코드를 다시 살펴보니
ID가 video-title인 곳에서 제목과 URL의 정보가 모두 담겨져 있는 것을 알 수 있습니다.
◆ 코드 작성하기
자 이제 코드를 작성해보겠습니다.
먼저 동영상에 해당하는 가장 큰 범위의 ID를 가지고 있던 dismissble 부분을 불러와서 저장하겠습니다.
titles = driver.find_elements(By.CSS_SELECTOR, "#dismissible")
그런 후
for 문을 이용해 titles에 저장되어 있는 내용을 하나씩 불러와 title에 담습니다.
titles에는 ID가 dismissible인 부분이 모두 저장되어 있으므로 하나씩 불러와 title에 담아주어야 합니다.
for title in titles:
다음으로 제목을 추출하기위해 웹페이지 소스코드(위 그림)에서 property가 title인 부분과
property가 href인 부분을 불러와서 저장합니다.
main_title = title.find_element(By.CSS_SELECTOR, "#video-title").get_property("title")
tube_url = title.find_element(By.CSS_SELECTOR, "#video-title").get_property("href")
그리고 출력을 해줍니다.
print(main_title, " ", tube_url)
자 이제 현재 웹페이지에서 유튜브 동영상의 제목과 URL을 가지고 올 수 있습니다.
마지막으로 지난번에 포스팅했던 웹페이지 자동스크롤하기와 결합하면
수많은 동영상의 제목과 주소를 가지고 올 수 있습니다.
마지막으로 코드를 실행한 결과입니다.

'파이썬(Python)' 카테고리의 다른 글
| [ 크롤링-Selenium, BeautifulSoup ] 파이썬 Selenium과 BeautifulSoup 함께 사용하기 (0) | 2022.10.21 |
|---|---|
| [ 크롤링-Selenium ] 파이썬 유튜브 크롤링 결과 엑셀파일 저장하기 (0) | 2022.10.20 |
| [ 크롤링-Selenium ] 파이썬 셀레니움 웹페이지 자동 스크롤 하기(Python Selenium scroll webpage) (0) | 2022.10.18 |
| [ 크롤링-Selenium ] 웹 크롤링 파이썬 네이버 페이지 클릭하기, 검색어 입력하기 (0) | 2022.10.14 |
| [ 크롤링-Selenium ] 웹 크롤링 파이썬 셀레니움 webdriver 자동 설치(Python selenium webdriver auto-install) (0) | 2022.10.11 |