판다스의 read_excel() 함수는
엑셀 파일의 데이터를 읽는 함수입니다.
엑셀 파일을 조작할 때 반드시 필요한 함수입니다.
다른 곳에서 정리한 데이터를 받는 것이 아닌 직접 데이터를 엑셀 파일에서 읽어오려면
read_excel() 함수를 사용합니다.
준비된 시트 내용
왼쪽 : (시트이름) 복사본
오른쪽 : (시트이름) 원본
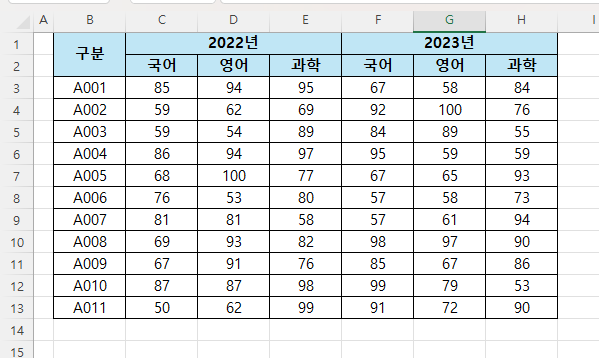
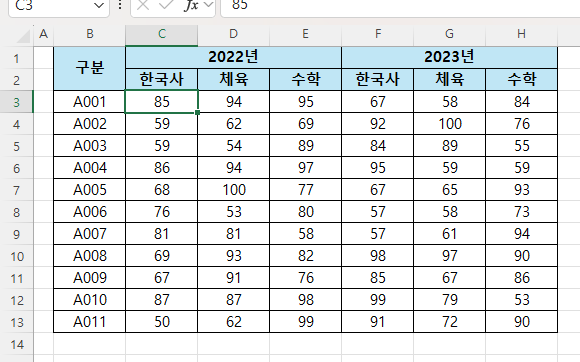
총괄 정리
| 사용법 | 기능 설명 | 비고 |
| io | pd.read_excel('파일경로') | 읽어올 엑셀 파일의 경로를 지정합니다. |
| sheet_name | pd.read_excel('파일경로', sheet_name='Sheet1') | 불러올 시트를 지정합니다. 기본값은 첫 번째 시트이며, 문자열(시트 이름) 또는 정수(시트 번호)로 지정할 수 있습니다. 여러 시트를 불러올 경우 리스트나 None을 사용할 수 있습니다. |
| header | pd.read_excel('파일경로', header=0) | 데이터프레임의 열 이름을 지정하는 인자입니다. 기본값은 0으로, 첫 번째 행이 열 이름으로 사용됩니다. 다른 행을 열 이름으로 사용하려면 해당 행의 인덱스를 지정합니다. |
| index_col | pd.read_excel('파일경로', index_col=0) | 데이터프레임의 인덱스로 사용할 열을 지정합니다. 기본값은 None으로, 자동으로 RangeIndex가 생성됩니다. |
| usecols | pd.read_excel('파일경로', usecols='A:C') | 가져올 열을 수동으로 지정합니다. 열의 알파벳 또는 인덱스 번호를 사용하여 특정 열만 선택할 수 있습니다. |
| names | pd.read_excel('파일경로', names=['A', 'B']) | 데이터프레임의 열 이름을 수동으로 지정합니다. 지정한 리스트의 길이는 데이터의 열 수와 일치해야 합니다. |
| dtype | pd.read_excel('파일경로', dtype={'A': str}) | 특정 열의 데이터 타입을 미리 지정할 수 있습니다. 딕셔너리 형태로 열 이름과 타입을 설정합니다. |
| na_values | pd.read_excel('파일경로', na_values=['NA']) | 결측치로 취급할 값을 지정합니다. 이 값들은 NaN으로 변환됩니다. |
| skiprows | pd.read_excel('파일경로', skiprows=1) | 파일에서 읽어올 때 처음 몇 개의 행을 건너뛰도록 설정합니다. |
| engine | pd.read_excel('파일경로', engine='openpyxl') | 엑셀 파일을 읽기 위해 사용할 엔진을 명시적으로 지정할 수 있습니다. 주로 'openpyxl'이나 'xlrd'를 사용합니다. |
| nrows | pd.read_excel('파일경로', nrows=5) | 읽어들일 행 수 지정, 정수값 사용 |
| na_filter | pd.read_excel('파일경로', na_filter=False) | 결측치 감지 여부, 기본값 True |
파일 경로 지정
아래 그림과 같이 파일 경로를 지정하여 데이터를 불러올 수 있습니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx")
print(df)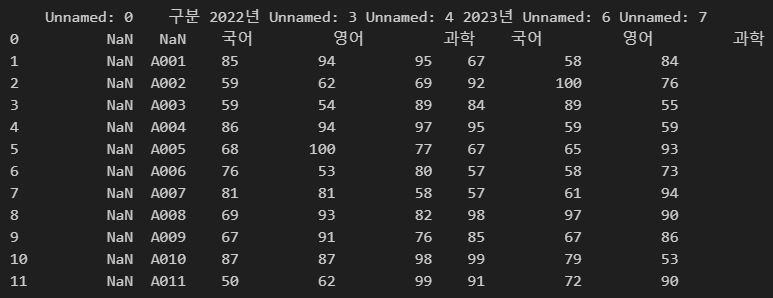
기본적으로 파일 경로 외에 아무것도 지정하지 않으면,
첫 번째 시트를 불러옵니다.
이는 다음에 설명할 sheet_name의 인자가 기본으로 첫 번째 시트를 가리키기 때문입니다.
불러올 시트 지정
예시 파일에는 시트가 두개 있습니다.
앞서 말씀드린 것 처럼 별도의 지정이 없으면 첫 번째 시트를 불러옵니다.
시트를 지정해서 불러오고 싶을 때는 시트 번호를 입력하거나,
시트 이름을 입력해서 불러올 수 있습니다.
기본적으로 지정하지 않으면
sheet_name = 0 입니다.
아래 코드와 같이 sheet_name = 1로 지정하면
두 번째 시트를 불러옵니다. ※ 첫 번째 시트는 0부터 시작합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", sheet_name=1)
print(df)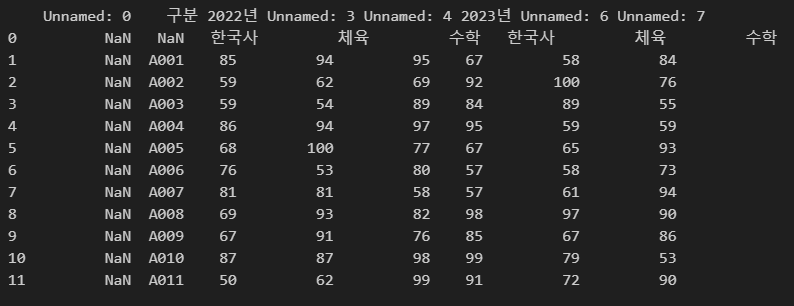
시트 이름으로 불러올 수도 있습니다.
결과는 위와 동일합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", sheet_name="원본")
print(df)
만약 None을 지정하면 모든 시트를 한 번에 불러옵니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", sheet_name=None)
print(df)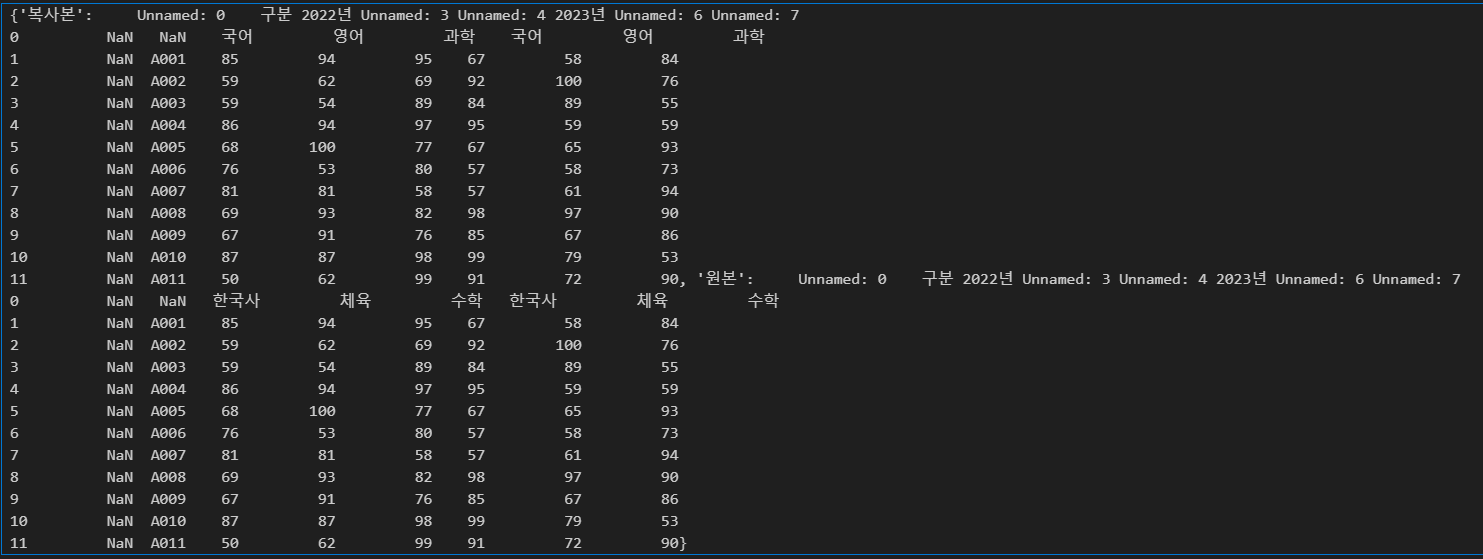
제목행 출력
데이터에서 제목행은 중요합니다.
판다스에서는 헤더라고 말하며 기본적으로 제일 첫 번째 행이 헤더로 지정됩니다.
헤더를 지정하기 위해서는 header 인자에 값을 주면 됩니다.
아래 코드를 실행하면 다음과 같이 결과가 출력됩니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=0)
print(df.columns)
header를 1로 바꾸어 보면 다음과 같이 결과가 나타납니다.

제목이 되는 행은 중복된 값이 있으면 안 되므로,
pandas에서 자동으로 숫자를 붙여 제목행을 구분해 줍니다.
아래와 같이 제목행을 1행. 즉 2번째 행으로 지정하고 출력하면
다음과 같이 결과가 나타납니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1)
print(df)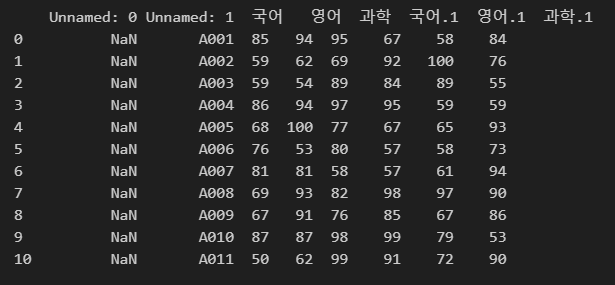
인덱스 열 지정
지금까지 출력 결과를 보시면
맨 앞에 1~10까지의 숫자가 적혀 있습니다.
이것을 INDEX라고 합니다.
INDEX를 지정하는 인자는 index_col이며 기본값은 None입니다.
만약 A001 ~ A011을 INDEX로 만들고 싶다면
아래와 같이 코드를 작성하시면 됩니다.
A001~A011은 B열에 위치하므로 두 번째인 1을 사용합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1, index_col=1)
print(df)
특정 열만 가지고 오기
특정 열만 지정해서 가져올 수 있으며
이때 사용하는 인자는 usecols입니다.
아래 코드에서는 A열 ~ D열의 자료를 가지고 오게 했습니다.
header는 1로 지정했습니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1, usecols="a:d")
print(df)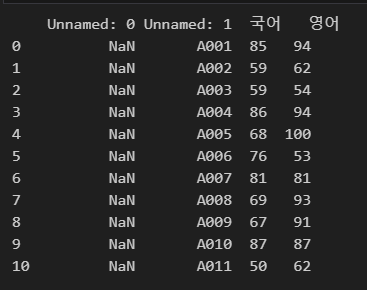
열 이름을 수정하기
아래 그림과 같이 열 이름이 지정되어 있을 경우 바꾸어야 할 필요가 있습니다.
이때 names 인자에 값을 리스트 형태로 주어 열 이름을 바꿀 수 있습니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1, names=["", "이름", "2022-국어", "2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"])
print(df)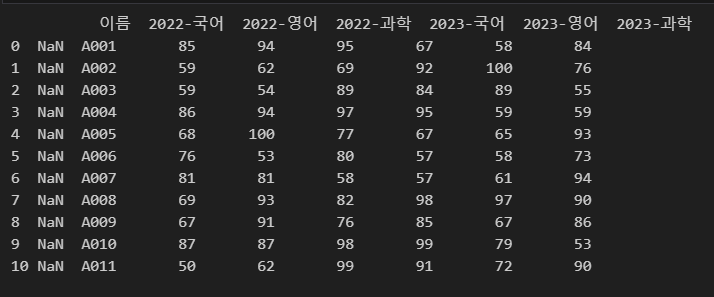
열의 개수와 names로 지정한 열의 이름은 같아야 합니다.
그렇지 않을 경우 아래와 같은 현상이 발생합니다.
아래 코드는 앞에 세 개 열의 제목을 누락시킨 상태입니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1, names=["2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"])
print(df)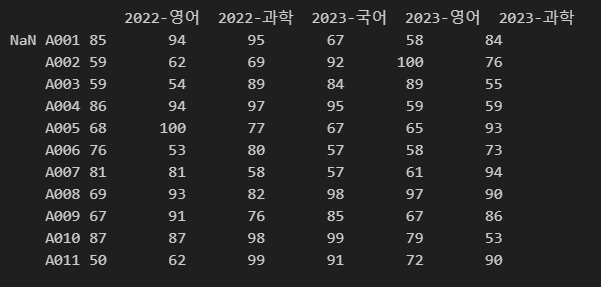
데이터 타입 지정
각 열의 데이터 타입을 지정할 수 있습니다.
적은 양의 데이터를 다룰 때보다는 대용량의 데이터를 다룰 때 필요합니다.
또한, 계산의 정확성을 위해 데이터 타입을 지정할 수 있습니다.
dtype 인자를 사용하며 딕셔너리 형태로 데이터를 입력하면 됩니다.
대략 다음과 같은 데이터 타입을 지정할 수 있습니다.
int: int64, int32, int16, int8
float: float64, float32
str: string, object
bool: boolean
datetime64: 날짜/시간
category: 범주형 데이터
데이터 타입은 딕셔너리 형태로 열 이름과 타입을 설정합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1,
names=["", "이름", "2022-국어", "2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"],
dtype={"": "string", "이름": "string", "2022-국어": 'int8', "2022-영어": 'int8', "2022-과학": 'int8', "2023-국어": 'int8', "2023-영어": 'int8', "2023-과학": 'int8'})
print(df)
만약 텍스트 형태의 데이터를 int 형태로 지정하면 에러가 발생합니다.
이 부분은 간단한 데이터를 다룰 때에는 크게 신경 쓰지 않아도 되지만,
대용량의 데이터를 다룰 때에는 메모리, 속도, 정확성 등에 영향을 미치므로
정해주는 것이 좋을 수 있습니다.
결측치로 처리할 것을 지정
결측치는 데이터 값이 누락된 상태를 의미합니다.
일반적으로 공백과 같은 데이터는 자동으로 결측치로 인식하여
NaN을 출력합니다.
na_values 인자를 사용하며, 리스트 형태 또는 딕셔너리 형태로 값을 받습니다.
그런데 공백이 아닌 경우도 있습니다.
예를 들어 데이터에 "없음"으로 표기를 하는 경우도 있고
"해당 없음"이런 것으로 표기할 수도 있습니다.
이런 것들은 결측치로 처리할 필요가 있을 수 있습니다.
아래 코드에서는 임의로 A001과 A002의 데이터를 결측치로 설정해 보았습니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1,
names=["", "이름", "2022-국어", "2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"], na_values=["A001", "A002"])
print(df)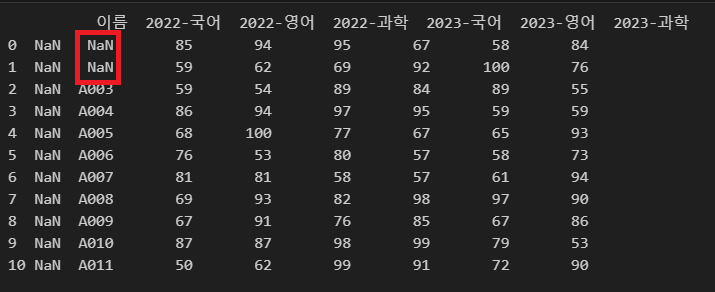
만약 특정 열의 어떤 값만 결측치로 처리하고 싶다면
아래와 같이 코드를 작성하시면 됩니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1,
names=["", "이름", "2022-국어", "2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"],
na_values={ '이름' : ['A001', 'A008']})
print(df)
na_value는 기본적으로 문자열 비교를 수행하므로,
숫자 형태에서는 동작하지 않을 수도 있습니다.
이 경우 아래 코드와 같이 작성해서 처리할 수 있습니다.
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", header=1,
names=["", "이름", "2022-국어", "2022-영어", "2022-과학", "2023-국어", "2023-영어", "2023-과학"])
df['2022-국어'] = df['2022-국어'].replace([59, 60, 61], np.nan)
print(df)
처음 몇 개 행을 건너뛰고 읽어오기
파일에서 처음 몇 개 행이 불필요한 데이터가 있을 경우
그 부분을 제외하고 읽어올 수 있습니다.
다시 별도의 인자를 주지 않고 파일 경로만 주었을 경우의 결과입니다.
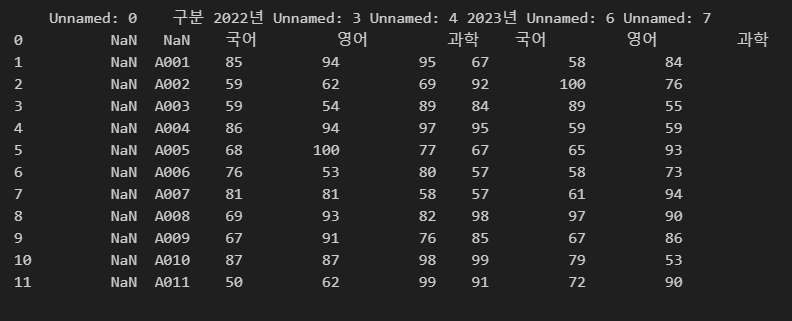
제일 첫 번째 행은 제목 행이 아니기에 첫번째 행을 제외하고 불러오겠습니다.
이럴 경우 skiprows 인자를 사용합니다.
첫 번째 행을 불러오지 않기 위해서는 0부터 시작이 아니라 1부터 시작을 합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", skiprows=1)
print(df)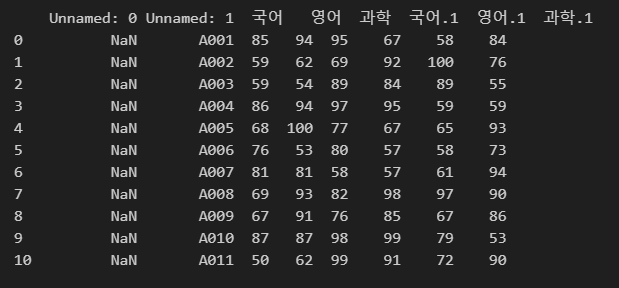
경우에 따라서 header 인자로 제목행을 지정해도 되고
skiprows로 제목행을 지정할 수도 있습니다.
엑셀 파일을 읽기 위한 엔진 명시
판다스만 설치한다고 해서 엑셀파일을 읽을 수 있지는 않습니다.
xlsx 파일을 읽고 처리하기 위해서는 openpyxl 라이브러리가 설치되어야 하고
xls 파일을 읽고 처리하기 위해서는 xlrd 라이브러리가 설치되어 있어야 합니다.
xlsb 파일을 읽고 처리하기 위해서는 pyxlsb 라이브러리가 설치되어 있어야 합니다.
import로 불러와야 하는 것은 아니지만,
설치는 되어 있어야 합니다.
engine 인자는 이러한 엔진을 명시적으로 지정해 줄 수 있습니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", skiprows=1, engine='openpyxl')
print(df)
지정하지 않으면 pandas는 자동으로 엔진을 지정합니다.
일반적으로 대규모 데이터 처리가 아닐 경우에는 지정하지 않아도 됩니다.
아래 내용은 참고만 하시면 됩니다.
아래와 같이 엔진을 지정하시면 다른 라이브러리 없이 모두 읽을 수 있으며,
속도도 더 빠를 겁니다.
pip install python-calamineimport pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", skiprows=1, engine='calamine')
print(df)
읽어 들일 행 수 지정
읽을 행 개수를 지정할 수 있습니다.
nrow 인자를 사용합니다.
import pandas as pd
df = pd.read_excel(r"C:\Users\karur\Desktop\pandas.xlsx", skiprows=1, engine='calamine', nrows=5)
print(df)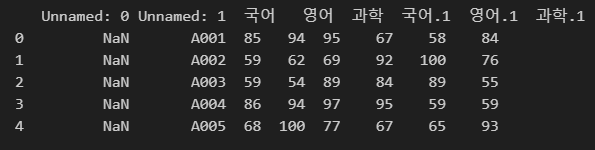
결측치 감지 끄기
판다스는 자동으로 비어있는 값을 결측치로 감지하지만,
na_filter에 FALSE 값을 주면 결측치 감지를 끌 수도 있습니다.
여기를 방문하시면 더 많은 파이썬 관련 자료를 확인할 수 있습니다.
'파이썬(Python)' 카테고리의 다른 글
| [ 자작 프로그램 ] 엑셀 파일의 시트 합치기 프로그램 (3) | 2024.11.14 |
|---|---|
| [ CustomTkinter ] Customtkinter 메뉴 만들기 (0) | 2024.11.13 |
| [ Tkinter, ttk, CustomTkinter ] 각 라이브러리 위젯 비교 및 지원 여부 (1) | 2024.11.10 |
| [ Selenium ] 크롬 브라우저 실행 시 내 정보를 유지한 채로 브라우저 띄우기 (3) | 2024.11.06 |
| [ Selenium ] CSS Selector(CSS 셀렉터)를 사용하여 웹 페이지 요소 찾기 (0) | 2024.11.05 |