Selenium 모듈을 사용하여 요소를 찾기 위해서 아래 두 함수를 사용합니다.
find_element()
find_elements()
위 두 함수를 사용하기 위해서는 아래 모듈을 import 해주어야 합니다.
from selenium.webdriver.common.by import By
find_element() 와 find_elements()의 차이점은 다음과 같습니다.
find_element()는 여러개의 요소가 있어도 첫번째 요소의 위치를 반환합니다.
find_elements()는 여러개의 요소를 list 형태로 반환합니다.
요소의 위치를 찾는 방법은 여러가지가 있습니다.
① ID 사용 : find_element(By.ID, "id")
② NAME 사용 : find_element(By.NAME, "name")
③ XPATH 사용 : find_element(By.XPATH, "xpath")
④ LINK_TEXT 사용 : find_element(By.LINK_TEXT, "link text")
⑤ PARTIAL_LINK_TEXT 사용 : find_element(By.PARTIAL_LINK_TEXT, "partial link text")
⑥ TAG_NAME 사용 : find_element(By.TAG_NAME, "tag name")
⑦ CLASS_NAME 사용 : find_element(By.CLASS_NAME, "class name")
⑧ CSS_SELECTOR 사용 : find_element(By.CSS_SELECTOR, "css selector")
find_element() 함수를 예로 들었으나, find_elements()도 동일하게 사용됩니다.
제가 자주 도움을 받는 w3school 홈페이지 메인화면의
검색어 입력 부분을 예로 들어보겠습니다.

해당 부분의 소스는 다음과 같습니다.

먼저 ID를 사용해 보겠습니다.
해당 부분의 ID는 [ search2 ]입니다.
driver.find_element(By.ID, "search2").send_keys("파이썬")
위 코드를 실행하면 검색어 입력 창에 [ 파이썬 ]이 입력이 됩니다.
다음은 XPATH 입니다.
해당 부분에 마우스 오른쪽 버튼을 눌러 아래와 같이 [ XPath 복사 ]를 눌러줍니다.

driver.find_element(By.XPATH, '//*[@id="search2"]').send_keys("파이썬")
파란색 부분이 [ XPath 복사 ]를 통해 복사된 값입니다.
위 코드를 실행하면 동일하게 검색어 입력창에 [ 파이썬 ]이 입력됩니다.
다음은 CSS_SELECTOR를 사용하는 방법입니다.
XPath 사용과 동일하게 다음 그림과 같이 [ selector 복사 ]를 눌러줍니다.
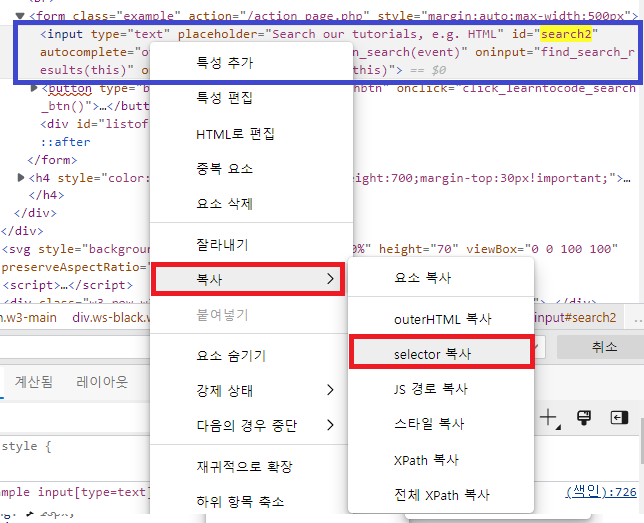
driver.find_element(By.CSS_SELECTOR, '#search2').send_keys("파이썬")
파란색 부분이 [ selector 복사 ]를 통해 복사한 값입니다.
위 코드도 검색창에 [ 파이썬 ]을 입력합니다.
다음은 CLASS_NAME를 사용하는 방법입니다.
아래 그림은 검색어 입력 창 옆에 있는 버튼에 해당하는 부분입니다.
class 이름은 [ fa fa-search ]입니다.

driver.find_element(By.ID, "search2").send_keys("python")
driver.find_element(By.CLASS_NAME, 'fa.fa-search').click()
위 코드는 검색어에 [ python ]을 입력하고 버튼을 클릭하는 코드입니다.
CLASS_NAME 사용시 해당 class에 빈칸이 있다면 [ . ]으로 채워줘야 합니다.
다음은 LINK_TEXT 와 PARTIAL_LINK_TEXT 사용방법입니다.
네이버 메인 페이지를 예로 들겠습니다.

위 그림은 네이버 메인 페이지의 일부입니다.
[ 부동산 ]을 클릭하면 다른 페이지로 연결되게 되어 있습니다.
URL은 모르지만 그 URL에 연결하기 위해서는
[ 부동산 ]이라는 글자를 누르면 됩니다.
여기서 TEXT가 [ 부동산 ]입니다.
driver.find_element(By.LINK_TEXT, "부동산").click()
위 코드를 실행하면 [ 부동산 ]을 클릭합니다.
driver.find_element(By.PARTIAL_LINK_TEXT, "부동").click()
PARTIAL_LINK_TEXT를 사용하면 단어의 일부만 사용해도 클릭이 가능합니다.
※ 위 예는 미리 해당 단어가 사용될 수 있는 것을 알고 예로 든 것입니다.
※ 다른 사이트의 경우 중복된 단어가 있을 때 제대로 동작이 되지 않을 수 있습니다.
다음은 NAME 사용방법입니다.
네이버 메인페이지 검색어 입력 창을 예로 들겠습니다.
아래 그림은 검색어 입력 창 부분입니다.
NAME은 [ query ]입니다.

driver.find_element(By.NAME, "query").send_keys("파이썬")
위 코드를 실행하면 네이버 검색창에 [ 파이썬 ]을 입력합니다.
다음은 TAG_NAME 사용방법입니다.
네이버 메인페이지를 예로 들겠습니다.
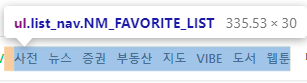
해당 부분은 다음과 같이 되어 있습니다.

[ 사전, 뉴스, 증권, 부동산, 지도, VIBE, 도서, 웹툰 ]이
[ ul ] 태그의 [ 클래스 list_nav NM_FAVORITE_LIST ]로 묶여 있고
사전, 뉴스 등 하나하나가 [ li ] 태그 안에 내용이 들어 있습니다.
먼저 list_nav NM_FAVORITE_LIST 클래스를 찾고
그 안의 [ li ]태그를 찾으면 모두 8개가 나올 것입니다.
k=driver.find_element(By.CLASS_NAME, "list_nav.NM_FAVORITE_LIST").find_elements(By.TAG_NAME, "li")
print(len(k))
print(type(k))
위 코드는 class 이름이 list_nav NM_FAVORITE_LIST 것 안에있는
모든 li 태그를 찾고
li 태그의 갯수와 타입을 출력합니다.
위 코드를 실행하면 li 태그 갯수는 8개 이고 타입은 list 임을 확인할 수 있습니다.
여기를 방문하시면 더 많은 파이썬 관련 자료를 확인할 수 있습니다.
'파이썬(Python)' 카테고리의 다른 글
| [ 크롤링-Selenium ] 파이썬 다음 블로그 크롤링(Python Selenium)(3)-페이지 이동 (0) | 2022.11.24 |
|---|---|
| [ 크롤링-Selenium ] 파이썬 다음 블로그 크롤링(Python Selenium)(2) (0) | 2022.11.23 |
| [ 크롤링-Selenium ] 파이썬 다음 블로그 크롤링(Python Selenium)(1) (0) | 2022.11.21 |
| [ 크롤링-Selenium ] Python Selenium get_attribute() 셀레니움 요소값 (0) | 2022.11.20 |
| [ 크롤링-Selenium ] selenium is_displayed(), 화면에 보이는지 여부 확인 (0) | 2022.11.19 |