request 라이브러리에서
GET 요청은 웹 서버에서 특정 정보를 가져올 때 사용하고
POST 요청은 웹 서버에 데이터를 전달하고 처리를 요청할 때 사용합니다.
전문적이고 자세한 내용보다는 어떻게 사용하는지
간단한 코드와 설명을 통해 알아보겠습니다.
웹 스크래핑의 간단한 지식이 필요할 수 있습니다.
GET 요청
먼저 네이버에 접속해서 간단한 검색어를 입력해 보겠습니다.
네이버 블로그에서 검색을 하기 위해
아래 그림과 같이 네이버 블로그에 접속을 했습니다.

이제 검색어를 입력해보겠습니다.
여기서 자세히 보셔야 할 부분은 URL입니다.
파이썬이라는 검색어를 입력하면 아래 그림과 같이 검색 결과가 나타납니다.

그리고 이 페이지의 URL은 다음과 같습니다.
https://section.blog.naver.com/Search/Post.naver?pageNo=1&rangeType=ALL&orderBy=sim&keyword=%ED%8C%8C%EC%9D%B4%EC%8D%AC
맨 마지막에 keyword=파이썬
이렇게 URL에 입력이 되어있습니다.
검색창에 입력하지 않고 URL에 직접 해당 부분을
keyword=자바
이렇게 변경하셔도 자바에 대한 검색 결과가 나타납니다.

변경된 URL은 다음과 같습니다.
https://section.blog.naver.com/Search/Post.naver?pageNo=1&rangeType=ALL&orderBy=sim&keyword=%EC%9E%90%EB%B0%94
다시 웹페이지를 살펴보면
아래 그림의 네모와 같이 다른 방식으로 검색 결과를 표시할 수도 있습니다.

하나씩 클릭해 보면 클릭할 때마다 URL이 바뀌는 것을 알 수 있습니다.
다시 파이썬을 검색하고 이번에는 최신순으로 정렬해 보겠습니다.

최신순으로 정렬하면
URL의 orderBy=recentdate로 바뀌게 됩니다.
다시 관련도순으로 정렬하면
URL의 orderBy=sim으로 바뀌게 됩니다.
이처럼 URL에 정보를 작성하여 응답을 받는 방법을
GET 방식이라고 합니다.
해당 URL에 직접 정보를 요청하므로
URL만 보아도 어떤 정보를 요청했는지 확인이 가능합니다.
POST 요청
보통 POST 요청 방식으로 작동하는 웹페이지는
URL이 바뀌지 않습니다.
아래 웹페이지를 예를 들어 보겠습니다.
토지정보를 확인할 수 있는 토지이음 사이트입니다.
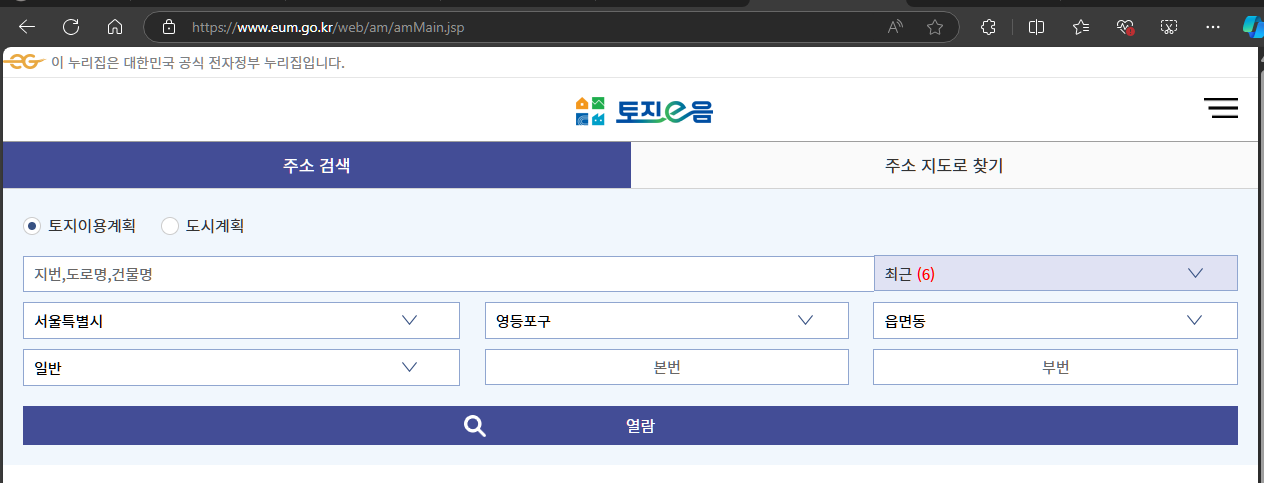
서울역의 지번을 한번 검색해 보겠습니다.
서울역 지번은 서울특별시 용산구 동자동 43-205로 검색이 됩니다.
해당 내용을 입력하고 검색을 하면
아래 그림과 같이 결과가 나타나지만 URL이 바뀌지 않습니다.
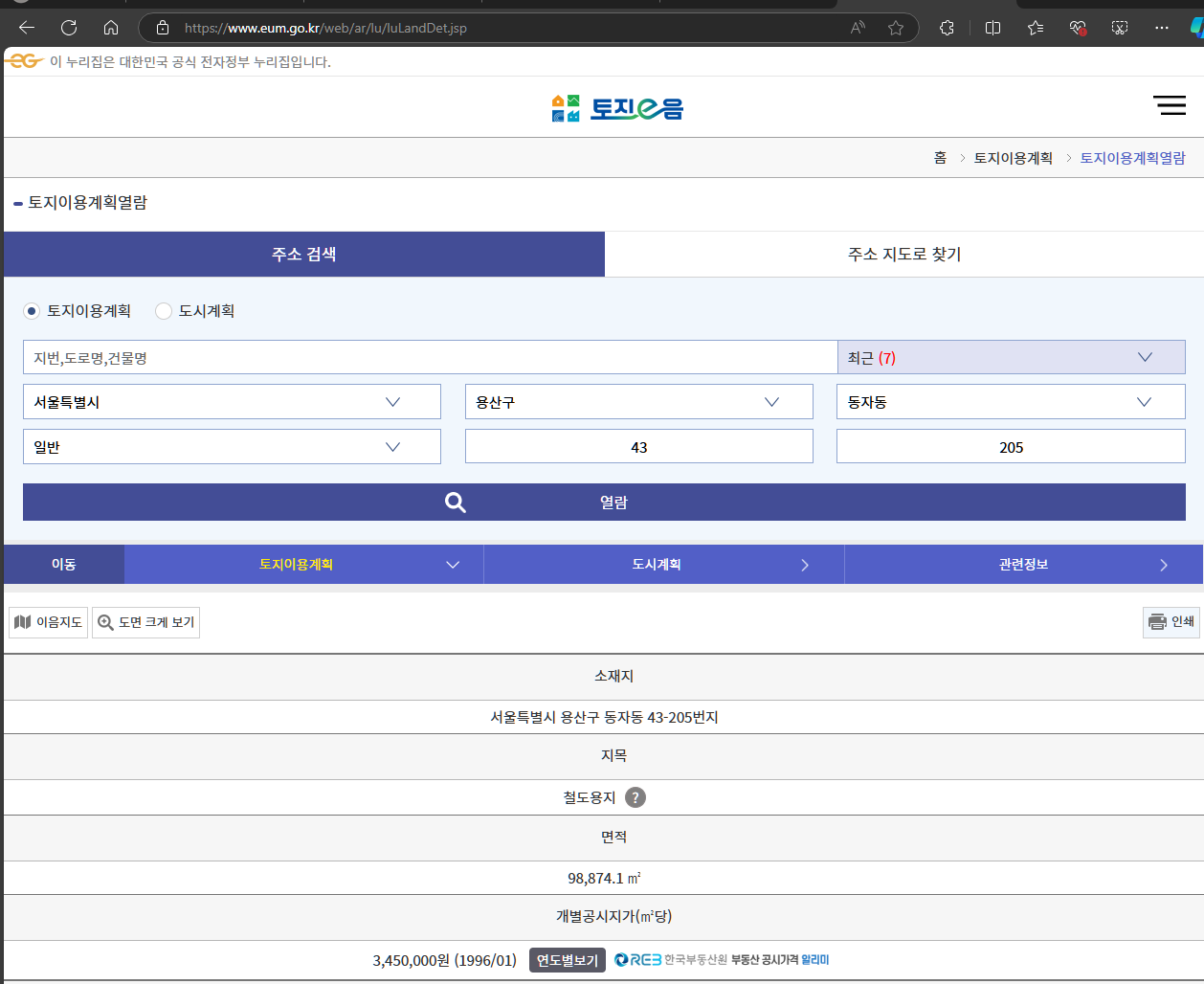
이 경우 입력된 정보가 GET 요청과 같이 URL을 통해 요청되는 것이 아니라
어디선가 눈에 보이지 않게 요청이 되고 있다고 추측할 수 있습니다.
F12키를 눌러 개발자 도구를 열고 네트워크 탭을 선택한 후
다시 한번 열람을 눌러줍니다.
※ 개발자 도구 실행 방법 : 개발자 도구 여는 방법
그러면 아래 그림과 같이 무언가 많은 것이 나타나는데
이 내용들은 입력 버튼을 눌러 정보를 전달했을 때 웹페이지에서 일어나는 일들을
하나씩 보여주는 것입니다.
맨 위에 나타난 것을 한번 클릭해 보면 아래 그림과 같이 정보를 확인할 수 있습니다.
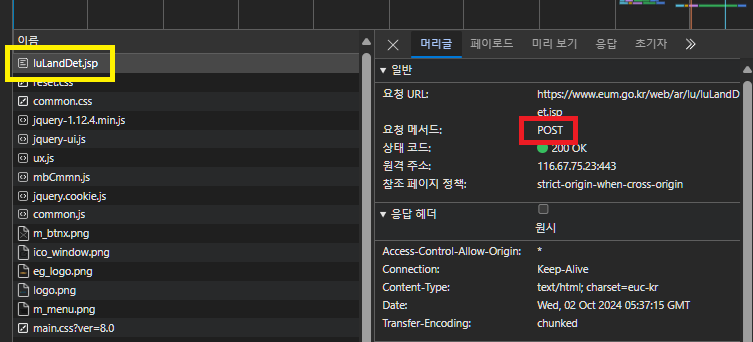
여기서 페이로드를 눌러보겠습니다.
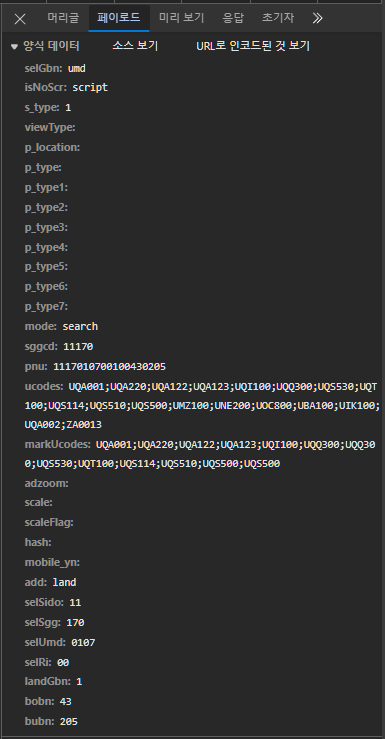
눈에 보이지는 않지만, 저런 자료들이 전달, 처리되고 있다는 의미입니다.
POST 요청 파이썬 코드
위 내용을 파이썬 request 라이브러리를 사용하여 구현해 보겠습니다.
import requests
# URL 설정
url = 'https://www.eum.go.kr/web/ar/lu/luLandDet.jsp'
# 요청에 사용할 데이터 설정
data = {
'selGbn': 'umd',
'isNoScr': 'script',
's_type': '1',
'viewType': '',
'p_location': '',
'p_type': '',
'p_type1': '',
'p_type2': '',
'p_type3': '',
'p_type4': '',
'p_type5': '',
'p_type6': '',
'p_type7': '',
'mode': 'search',
'sggcd': '11170',
'pnu': '1117010700100430205',
'ucodes': 'UQA001;UQA220;UQA122;UQA123;UQI100;UQQ300;UQS530;UQT100;UQS114;UQS510;UQS500;UMZ100;UNE200;UOC800;UBA100;UIK100;UQA002;ZA0013',
'markUcodes': 'UQA001;UQA220;UQA122;UQA123;UQI100;UQQ300;UQQ300;UQS530;UQT100;UQS114;UQS510;UQS500;UQS500',
'adzoom': '',
'scale': '',
'scaleFlag': '',
'hash': '',
'mobile_yn': '',
'add': 'land',
'selSido': '11',
'selSgg': '170',
'selUmd': '0107',
'selRi': '00',
'landGbn': '1',
'bobn': '43',
'bubn': '205'
}
# POST 요청 보내기
response = requests.post(url, data=data)
# 응답 확인
if response.status_code == 200:
print("Success!")
with open("result.txt", "w", encoding="utf-8") as file:
file.write(response.text) # 응답 내용을 파일에 기록
else:
print(f"Failed with status code: {response.status_code}")
data 부분은 페이로드에 나타난 내용을 파이썬 코드 형식에 맞게 붙여 넣었습니다.
그리고 결과를 result.txt 파일로 저장을 하는 코드입니다.
웹페이지에서 보이는 결과는 다음과 같습니다.
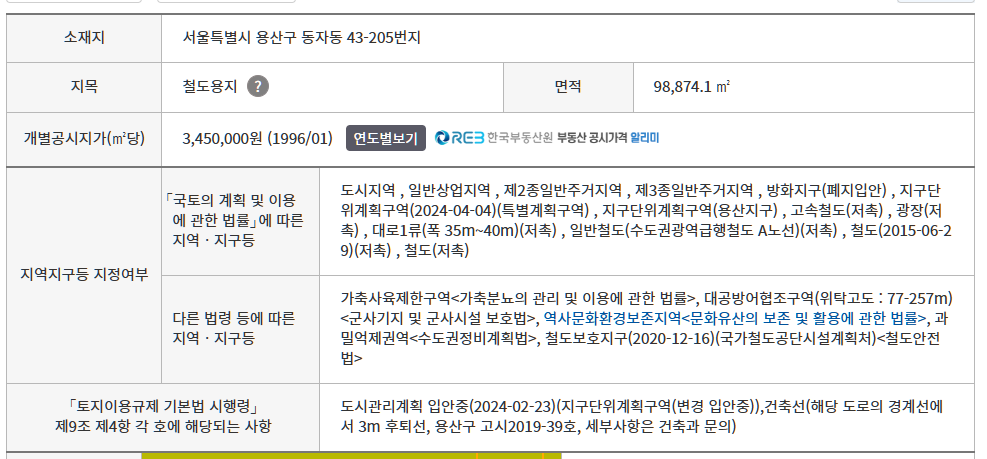
result.txt 파일에 저장된 내용을 보면
우선 소재지는 다음과 같이 출력이 되었습니다.
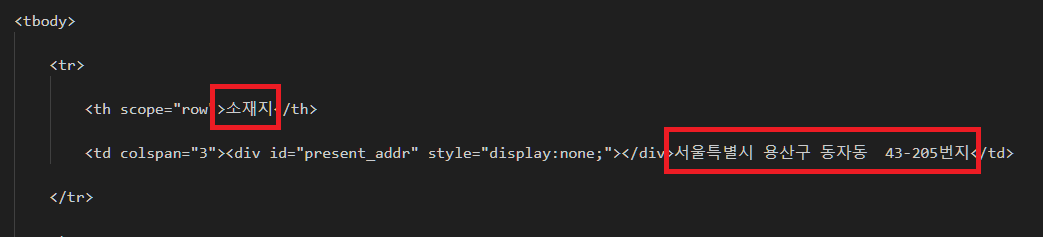
지목과 면적도 아래 그림과 같이 정상적으로 출력이 되었습니다.
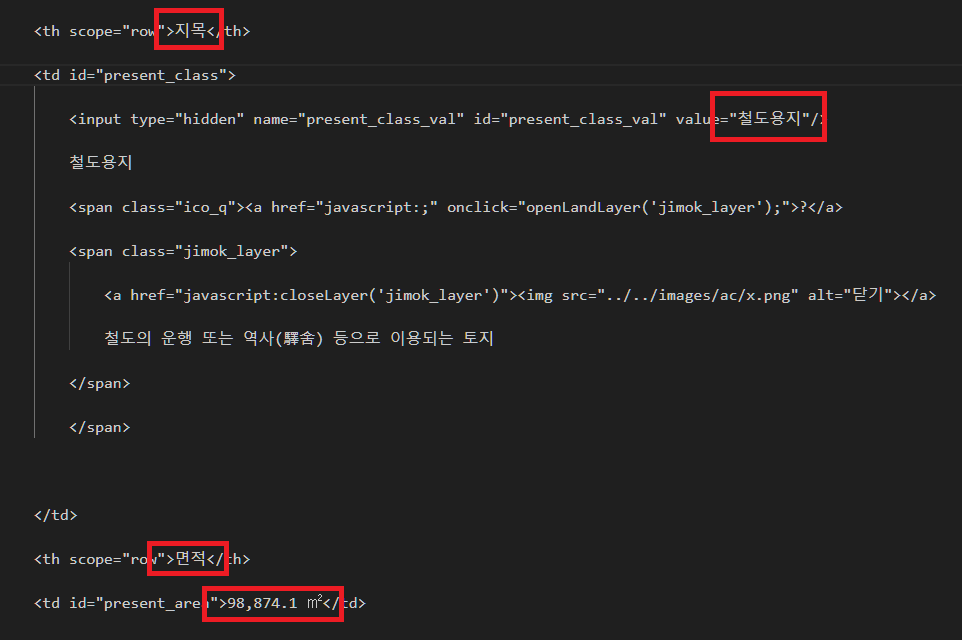
다만 다른 것들은 txt 파일 안에 정보가 들어있지만,
개별공시지가 등과 같은 것들은 정보가 없습니다.
이것은 개별공시지가가 내부적으로 별도의 요청에 의해 불러와지고
그 내용을 웹페이지에 표시하기 때문인 것으로 보입니다.
GET과 POST 방식이 어떻게 작동되는지
간단하게 알아 두면
웹스크래핑을 하는 데 많은 도움이 되실 겁니다.
여기를 방문하시면 더 많은 파이썬 관련 자료를 확인할 수 있습니다.
'파이썬(Python)' 카테고리의 다른 글
| [ ScreenInfo ] 파이썬으로 내 모니터 해상도 확인하기 : 모니터 정보 (2) | 2024.10.03 |
|---|---|
| [ Random ] 파이썬 웹스크래핑 무작위 시간만큼 기다리기 (0) | 2024.10.02 |
| [ 기본 ] 파이썬(Python) 매개변수와 인자의 활용 (0) | 2024.09.24 |
| [ Playwright ] 파이썬 웹페이지 자동화 : playwright 네이버 접속하기 (0) | 2024.09.19 |
| [ 기본 ] Python 함수의 기본 구조 : 매개변수(Parameter)와 인자(Argument) (1) | 2024.09.15 |