다음 블로그를 크롤링하는 방법에 대해 알아보겠습니다.
먼저 import할 모듈은 다음과 같습니다.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import time
import datetime
먼저 다음에서 [ 파이썬 ]을 검색을 합니다.
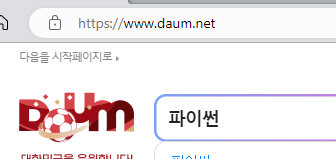
검색 후 마우스를 스크롤하여 조금 내려 [ 블로그 ]를 클릭합니다.

이때 주소창에 보이는 주소는 아래와 같습니다.
https://search.daum.net/search?p=1&q=%ED%8C%8C%EC%9D%B4%EC%8D%AC&col=blog&w=fusion&DA=TWC
먼저 url 변수를 선언해 줍니다.
url = "https://search.daum.net/search?p=1&q=%ED%8C%8C%EC%9D%B4%EC%8D%AC&col=blog&w=fusion&DA=TWC"
그리고 지난번의 웹드라이버 자동설치하기 포스팅을 참고하여 웹브라우저를 여는 코드를 작성합니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get(url)
time.sleep(3)
다음으로 웹사이트 구조가 어떻게 되어 있는 지 살펴보겠습니다.

<ul class="list_info ty_doc">안에 블로그 내용의 자료가 들어있는 것으로 보입니다.
이것을 토대로 삼아 하나씩 찾아보도록 하겠습니다.
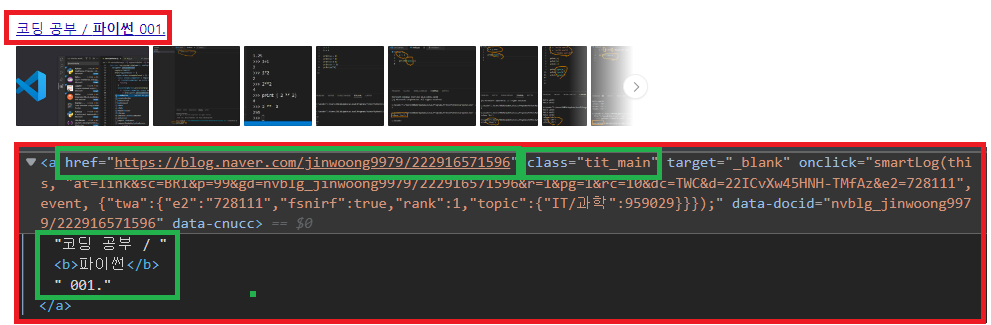
<a> 태그 안의 내용에 해당 블로그의 제목과 URL이 들어 있습니다.
그리고 class 이름은 [ tit_main ]입니다.
먼저 블로그의 제목을 추출해 보겠습니다.
main_datas = driver.find_element(By.CLASS_NAME, "list_info.ty_doc").find_elements(By.CLASS_NAME, "tit_main")
먼저 find_element(By.CLASS_NAME, "list_info.ty_doc")를 통해 블로그 검색결과의
전체적인 내용을 담고있는 부분에서 tit_main 이라는 이름을 가진 특정 클래스를 가진 부분들을
모두 검색해 main_datas에 담아줍니다.
main_datas 는 list형태이므로 그 안에 담긴 하나하나의 데이터에서 텍스트를 추출하겠습니다.
for datas in main_datas:
print(datas.text)
그럼 다음과 같이 블로그 제목들을 추출할 수가 있습니다.
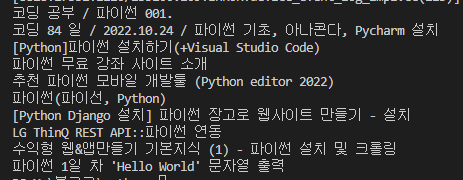
블로그의 제목을 추출했으니, 이제 URL을 추출해 보겠습니다.
for datas in main_datas:
print(datas.text)
print(datas.get_attribute("href"))
get_attribute() 함수를 이용하면 URL의 추출이 가능합니다.
get_attribute() 함수의 내용은 여기를 참고하시면 됩니다.
결과는 다음과 같습니다.

몇줄 안되는 코드로 다음 블로그 검색결과 첫페이지의
블로그 제목과 URL을 가지고 올 수 있습니다.
다음에는 아래 그림의 작성일자까지 가지고 오는 방법을 알아보도록 하겠습니다.

'파이썬(Python)' 카테고리의 다른 글
| [ 크롤링-Selenium ] 파이썬 다음 블로그 크롤링(Python Selenium)(2) (0) | 2022.11.23 |
|---|---|
| [ 크롤링-Selenium ] Python Selenium 요소 찾기(Locating Elements) (0) | 2022.11.22 |
| [ 크롤링-Selenium ] Python Selenium get_attribute() 셀레니움 요소값 (0) | 2022.11.20 |
| [ 크롤링-Selenium ] selenium is_displayed(), 화면에 보이는지 여부 확인 (0) | 2022.11.19 |
| [ 크롤링-Selenium ] Python Selenium 입력창 초기화, 입력 내용 지우기(clear) (0) | 2022.11.18 |