[ 기 본 내 용 ]
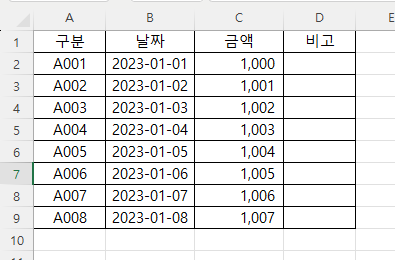
준비한 기본 엑셀파일은 다음 그림과 같습니다.

위 엑셀파일을 판다스(Pandas)를 사용해 불러와 보겠습니다.
판다스(pandas)를 사용하여 엑셀 파일을 불러오는 방법은
다음과 같습니다.
import pandas as pd
df = pd.read_excel("F:\블로그\python\pandas\pandas_exam.xlsx")
print(df)
판다스(Pandas)의 read_excel() 함수는
엑셀 파일을 읽어 DataFrame으로 변환하는 데 사용됩니다.
DataFrame을 간단하게 설명하면
2차원 데이터 구조로
행과 열을 가진 테이블로 보시면 됩니다.
자주 사용하는 엑셀 형식이
DataFrame 형식과 유사하다고 보시면 됩니다.
위 코드를 사용하여
엑셀파일을 불러왔을 경우
결과는 다음과 같습니다.

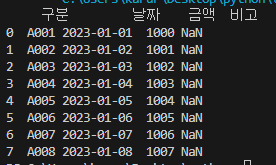
무언가 좀 난잡해 보이긴 하지만
잘 불러와 진 것은 맞습니다.
엑셀 파일과 비교해서 보겠습니다.
A열과 1행에 값이 없는 부분은
오른쪽 결과 그림의 빨간색 부분과 같이 나타납니다.
엑셀 파일의 형태를 조금 바꾸어 보겠습니다.
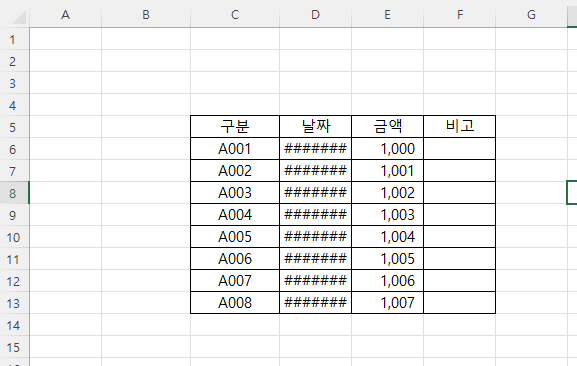
위 그림과 같이 [ A1 ] 셀 부터 데이터가 시작하도록
엑셀 파일을 조정하면
결과는 아래 그림과 같습니다.
이제 결과가 아까보다 깔끔하게 나타납니다.
[ 행과 열 조정하여 불러오기 ]
그러면 [ A1 ]셀부터 데이터가 시작하지 않는 엑셀파일을
깔끔하게 읽어오려면 어떻게 하는 지 알아보겠습니다.
엑셀 파일의 형식을 조금 바꾸어
아래 그림과 같은 엑셀파일을 만들어 보고
출력해 보겠습니다.
[ C5 ]셀부터 데이터가 시작되는
엑셀파일을 불러오면
아래 그림과 같이 나타납니다.

이런 형식의 파일을 제대로 불러오는 방법은
다음과 같습니다.
엑셀 파일은 [ C ]열부터 [ F ]열까지 데이터가 있습니다.
[ C열 ~ F열 ]까지의 데이터를 불러오는 방법은
다음과 같습니다.
import pandas as pd
df = pd.read_excel("F:\블로그\python\pandas\pandas_exam.xlsx", usecols="C:F")
print(df)read_excel() 함수의 인자로 [ usecols ]를 사용했으며,
그 값을 [ "C:F" ]로 지정하였습니다.
위 코드의 실행결과입니다.
열은 맞추어 졌으나 행이 맞지 않습니다.
이번에는 행을 정하는 방법을 알아보겠습니다.
import pandas as pd
df = pd.read_excel("F:\블로그\python\pandas\pandas_exam.xlsx", usecols="C:F", skiprows=4)
print(df)
read_excel() 함수의 매개변수로 [ skiprows ]를 사용하고
그 값을 [ 4 ]로 했습니다.
[ skiprows ] 매개변수는 건너뛸 행의 수를 지정하는 것입니다.
위 그림의 엑셀파일은
1행부터 4행까지는 데이터가 없으므로,
4개의 행을 건너뛰게 만들었습니다.
또 다른 방법으로는 [ header ] 매개변수를 사용하는 것입니다.
import pandas as pd
df = pd.read_excel("F:\블로그\python\pandas\pandas_exam.xlsx", usecols="C:F", header=4)
print(df)[ header ] 매개변수는 제목으로 사용할 행을 정하는 역할을 합니다.
시작 값이 [ 0 ]이므로
5번째 행을 제목행으로 사용하기 위해서는
매개변수 값을 [ 4 ]로 지정해야 합니다.
[ 참고사항 ]
마지막으로 판다스가 엑셀 데이터를 어떤 식으로
불러오는 지 알아보겠습니다.
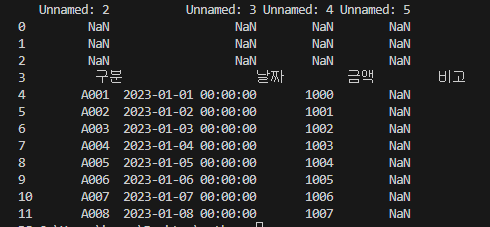
위 두 그림을 비교해보면
엑셀 파일에는 C열의 [ 구분 ]이라는 값 위에
4개의 빈칸이 있지만,
불러온 결과에는 [ 구분 ]이라는 값 위에
[ NaN ] 값이 3개만 있습니다.
이는 판다스로 엑셀파일을 불러올 때
첫번째 행을 제목행으로 인식하기 때문입니다.
또한
위 그림에서 오른쪽 결과 그림을 보시면
맨 앞에 [ 0 ~ 11 ]까지 엑셀 파일에는 없는 숫자가 있습니다.
이 숫자는 인덱스입니다.
즉 판다스가 해당 데이터는 몇개의 행으로 이루어져 있는지
말해주는 것입니다.
첫번째 행은 제목행이므로 데이터는 아닌 것으로 인식하고
시작값은 0입니다.
'파이썬(Python)' 카테고리의 다른 글
| [ 알고리즘 ] 1부터 n까지 숫자의 합 구하기, 1~100 / 1~1000 까지 숫자의 합 구하기, 알고리즘에 따라 걸리는 시간 (1) | 2023.11.29 |
|---|---|
| [ Pandas ] 판다스(Pandas)를 사용해 엑셀 특정시트, 여러 시트, 모든시트의 값 불러오기 (0) | 2023.11.04 |
| [ 알고리즘 ] 파이썬으로 소수 구하는 프로그램 만들기, 파이썬 소수 (0) | 2023.10.12 |
| [ Basic ] 파이썬 참과 거짓, Python True and False (0) | 2023.10.10 |
| [ Basic ] 파이썬 if, elif, else: 프로그래밍 초보자를 위한 if 문 가이드 (1) | 2023.10.02 |