pandas는 파이썬에서 사용되는 데이터를 조작하기 위한 라이브러리입니다.
pandas를 사용해서 대규모 데이터를 사용하고
복잡한 작업을 간결하게 수행할 수 있습니다.
Pandas의 데이터 구조
pandas는 Series와 DataFrame라는 두가지 데이터 구조를 제공합니다.
Series는 1차원 레이블이 지정된 배열이며,
DataFrame는 2차원 레이블이 지정된 배열입니다.
Series는 1차원 레이블 배열로 Pandas의 핵심 데이터 구조입니다.
간단한 예를 살펴보겠습니다.
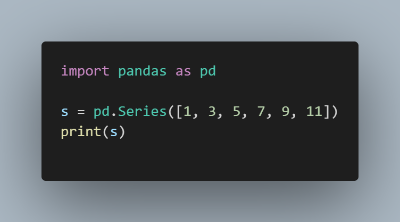
위 코드를 실행하면 다음과 같은 결과가 나타납니다.
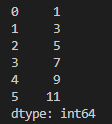
코드에서는 단순히 [ 1, 3, 5, 7, 9, 11 ]만 입력하였는데
앞에 [ 0, 1, 2, 3, 4, 5 ]라는 숫자가 붙어 있습니다.
앞에 있는 숫자는
값[ 1 ~ 11 ]에 접근하기 위한 인덱스라고 보시면 될 것 같습니다.
dtype는 현재는 int형 이지만, float, string 및 객체와 같은 모든 데이터 유형이 가능합니다.
인덱스를 사용하여 값에 접근할 수 있습니다.
쉽게 생각하면 데이터를 한줄로 쭉 나열한 형태로 보시면 됩니다.
한줄로된 데이터는 단순히 몇번째에 있는지만 알면 접근이 가능합니다.
물론 컴퓨터는 첫번째의 데이터를 [ 0 ]으로 시작합니다.
DataFrame은 2차원 데이터 구조입니다.
2차원 데이터 구조는 가로와 세로로 데이터를 나열한다고 생각하시면 됩니다.
우리가 흔히 접하는 엑셀의 구조와 같습니다.
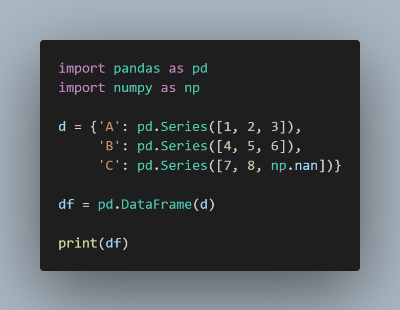
위 코드의 결과는 다음과 같습니다.
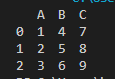
맨 앞에 세개의 행[ 0, 1, 2 ]가 있고
맨 위에 세개의 열[A, B, C ]가 있습니다.
간단하게 pandas는 1차원 배열과 2차원 배열을 다룰 수 있으며,
각각의 값은 색인을 통해 구분된다. 고 할 수있습니다.
데이터 불러오기
Pandas는 CSV 파일, Excel 파일, SQL 데이터베이스 또는 웹의 데이터를 불러올 수 있습니다.
이는 Pandas를 사용하면 거의 모든 데이터를 다룰 수 있다는 의미가 됩니다.
데이터 탐색
Pandas는 groupby, pivot_table, value_counts와 같이
데이터를 탐색하고 집계하는 기능을 제공합니다.
이런 함수를 사용하면
평균, 중위값, 표준 편차와 같은 통계를 쉽게 계산하고
이미지를 사용하여 데이터를 시각화 할 수도 있습니다.

위 코드를 사용하면 다음과 같은 결과가 나타납니다.

다음은 [ City ]를 기준으로 평균값을 구하는 코드입니다.
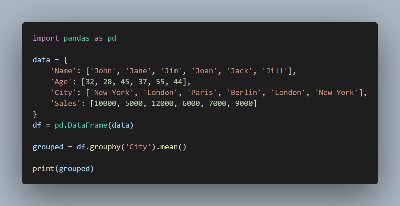
위 코드의 결과는 아래와 같습니다.
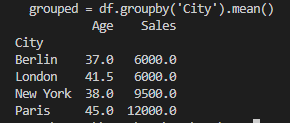
보시면 도시별로 [ Age ]와 [ Sales ]의 평균값을 계산해 준 것을 알 수 있습니다.
코드 한줄 추가로 말이죠.
데이터 변환
pandas는 데이터 프래임의 병합이나 결합 또는 연결과 같은
데이터 변환 기능을 제공합니다.
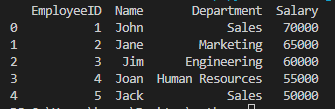
다음은 pandas를 사용하여 두개의 데이터 프레임을 병합하는 코드입니다.

첫번째 [ employee_data ]의 데이터프레임에
두번째 [ salary_data ]를 병합합니다.
기준은 [ EmployeeID ]입니다.
위 코드의 결과는 아래와 같습니다.
그 외
pandas는 데이터 프레임의 결측값 또는 null 값을 처리할 수 있습니다.
dropna(), fillna() 함수를 사용합니다.
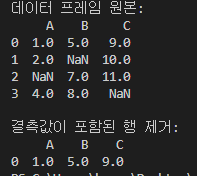
[ dropna()를 사용하여 결측값을 제거 ]
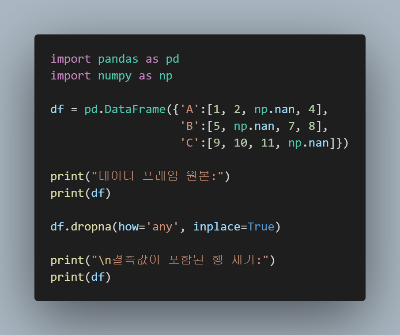
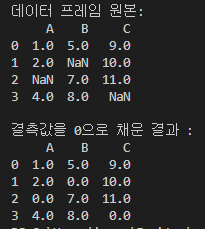
[ fillna()를 사용하여 결측값을 다른값으로 교체 ]

'파이썬(Python)' 카테고리의 다른 글
| [ Basic ] 파이썬 Dictionary 추가하기, 삭제하기 (0) | 2023.02.26 |
|---|---|
| [ Basic ] 파이썬(Python) Dictionary 만들고 수정, 접근하기 (0) | 2023.02.20 |
| [ Basic ] Methods와 Functions의 차이 학습 정리 (0) | 2023.02.06 |
| [ Tkinter ] tkinter 윈도우 화면 중앙에 위치 시키기 (0) | 2023.01.16 |
| [ Basic ] 파이썬에서 Print() 함수를 사용하는 다섯가지 방법 (0) | 2023.01.04 |